
Meine Begeisterung für Musik und Ton beruht ursprünglich auf meiner privaten Beschäftigung mit der Produktion von elektronischer Musik. Wobei besonders das Sounddesign hier sehr schnell meine größte Faszination ausmachte und auch gewissermaßen meine Produktionen charakterisierte.
Im Rahmen meiner Bachelorarbeit in meinem vorangegangen Computer Science Studium, beschäftigte ich mich, praktisch und theoretisch, mit KI basiertem Style-Transfer im Bereich der Musik-Produktion.
Dadurch, geschah auch mein erster stärker technischer Kontakt im Audio-Bereich, wodurch meine Faszination dafür nur verstärkt wurde.
Derzeit, liegt mein größtes Interesse auch im Rahmen des Studiums in der Audio-Programmierung und KI-Audio Anwendungen, was sich auch in meinen Projekten widerspiegelt.
2. Semester
KI-basierte Synthese von Elefanten-Rumbles
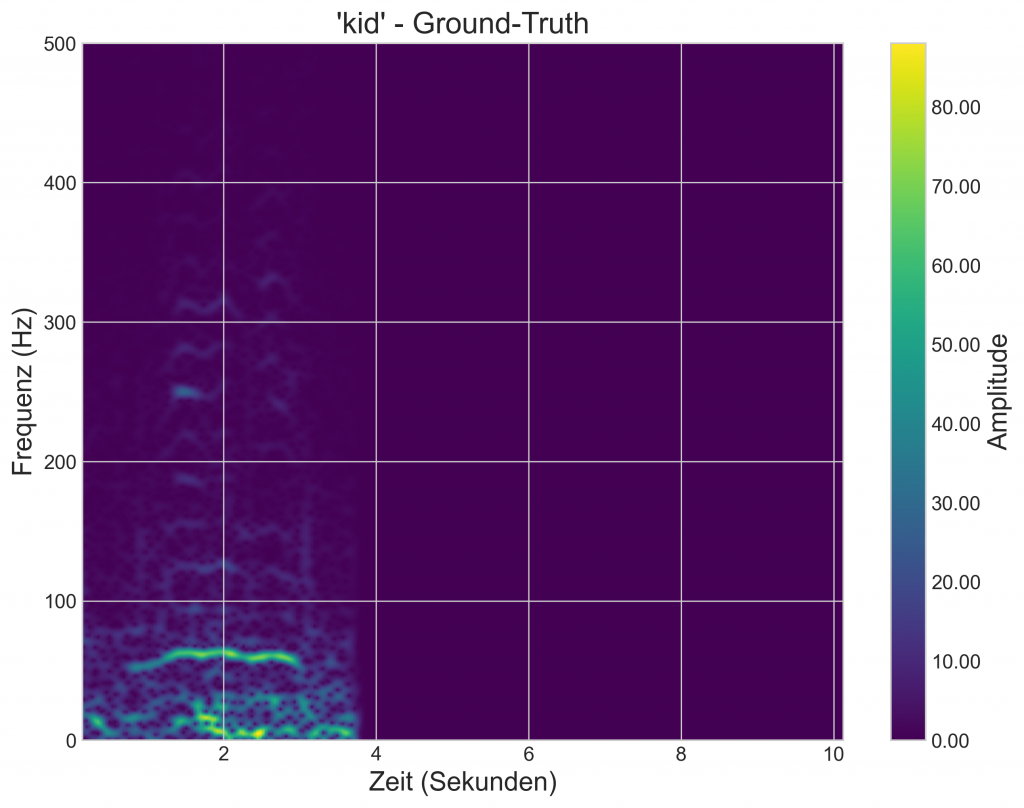
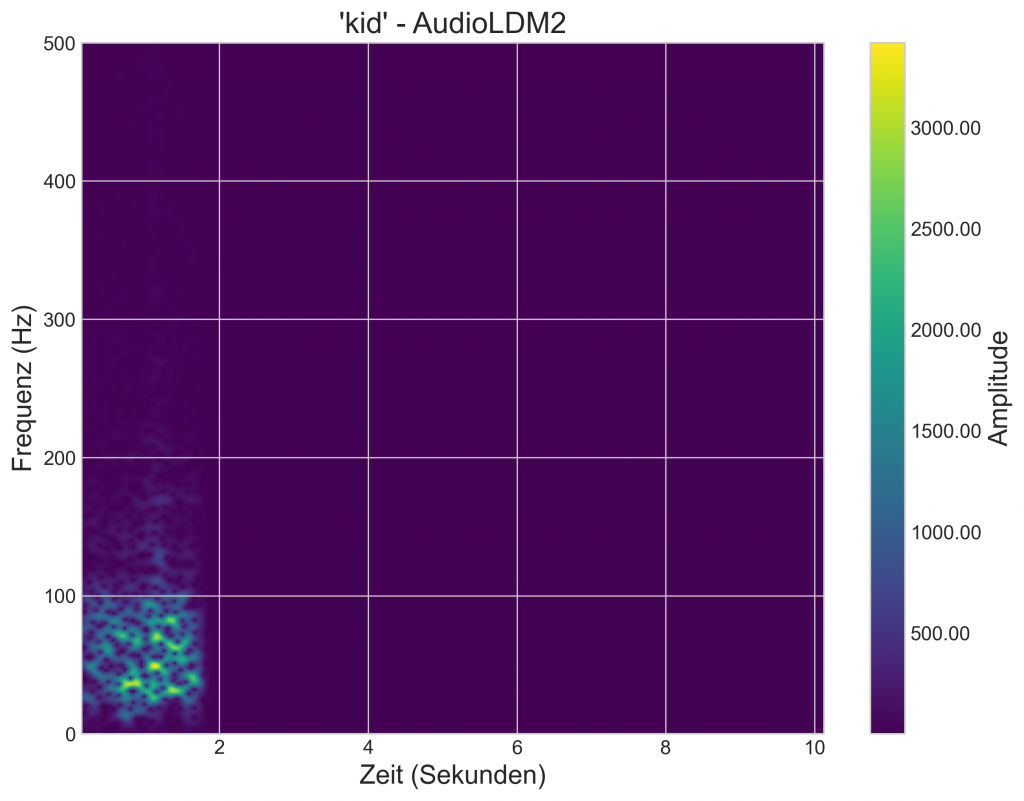
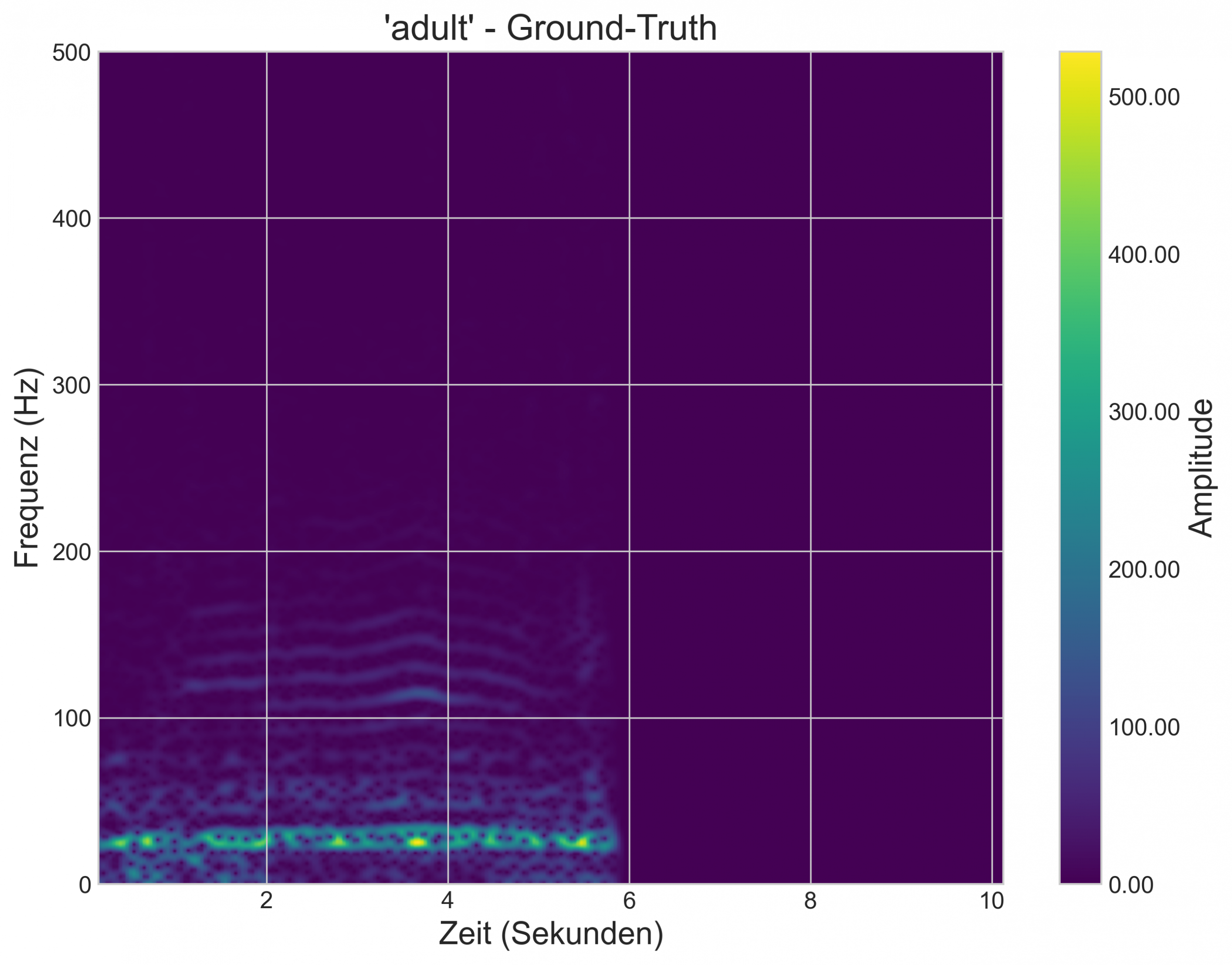
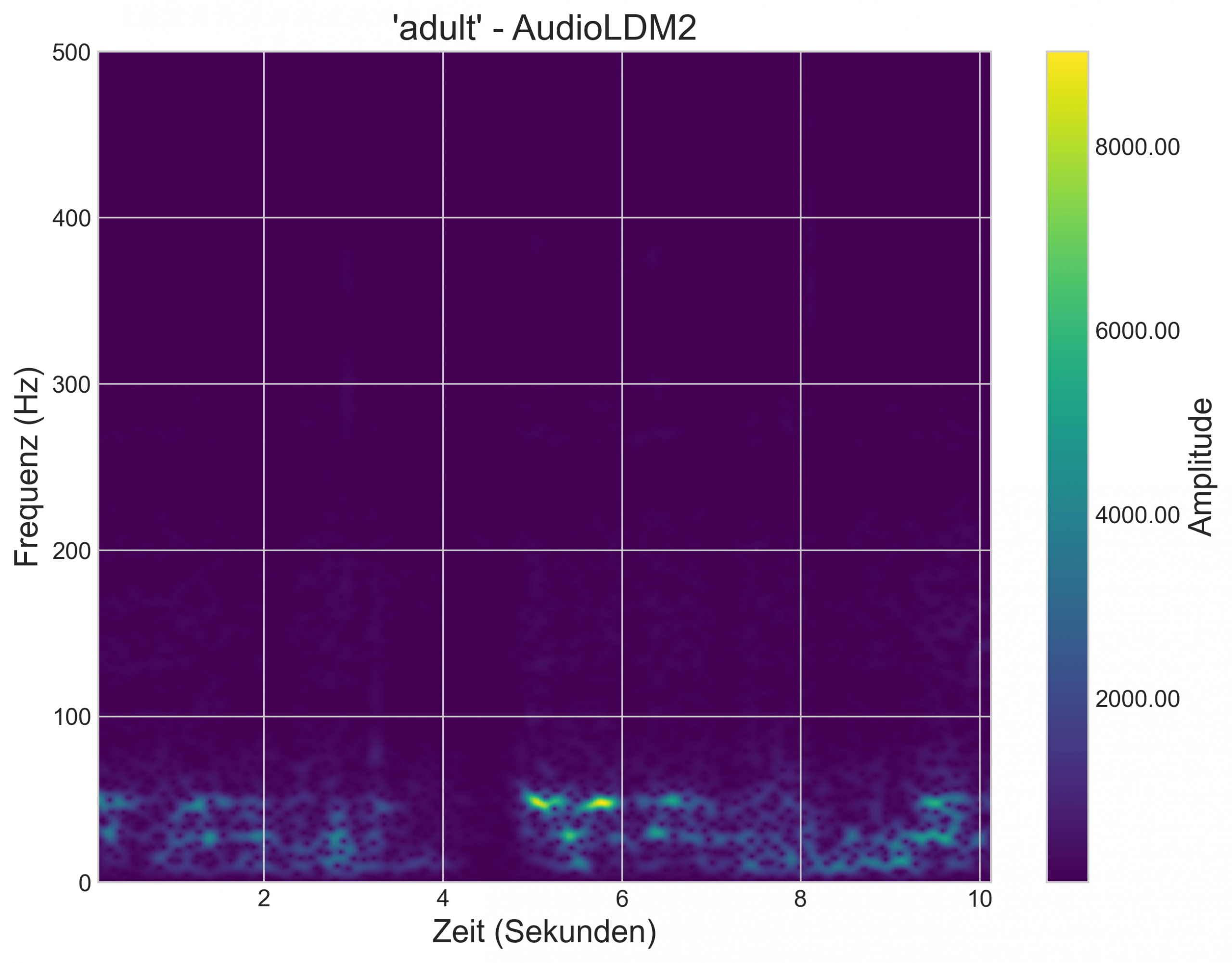
Im Rahmen meiner Mitarbeit am Forschungsprojekt Elecom befasste ich mich mit der Synthese von Elefanten-Vokalisationen mittels generativer KI. Das zugrundeliegende Ziel war es, ein Modell zu entwickeln, das die tieffrequenten „Rumbles“ von Elefanten erzeugt und dabei eine Konditionierung auf Basis der Altersklasse („kid“ vs. „adult“) ermöglicht.
Architektur und Implementierung
Hierfür fiel die Wahl auf die AudioLDM-2 Architektur, ein State-of-the-Art Text-to-Audio Modell. Eine wesentliche Herausforderung bestand darin, das teilweise undokumentierte Repository so zu adaptieren, dass ein Fine-Tuning des vortrainierten Modells mit dem Elefanten Datensatz möglich wurde. Die Umsetzung erfolgte in Python unter Verwendung des PyTorch-Frameworks.
Ergebnisse und Analyse
Trotz des stark limitierten Datensatzes von nur 188 kurzen klassifizierten „Rumbles“ zeigte sich, dass das Modell eine wesentliche Eigenschaft der Aufnahmen erlernte: die Generierung von tieffrequenten, Rumble-artigen Klängen.
Ein aufschlussreiches Beispiel hierfür ist der Test mit einem Out-of-Domain-Prompt wie „a ghost whispering“:
Obwohl die flüsternde Charakteristik erhalten bleibt, weist das generierte Audio ein klar dominantes, tieffrequentes Spektrum auf, was den Einfluss des Fine-Tunings zeigt.
Die auf die Zieldomäne konditionierten Prompts liefern überzeugende Ergebnisse. Der Vergleich der generierten Rumbles der jeweiligen Altersklassen, mit einem Ground-Truth-Beispiel zeigt deutliche Ähnlichkeiten in der grundlegenden Frequenzaufteilung:
Fazit und Ausblick
Das Projekt ist ein erfolgreicher Proof-of-Concept. Es zeigt, dass der Ansatz selbst mit einem kleinen Datensatz prinzipiell funktionieren kann und das Modell die grundlegenden Frequenz-Charakteristika der Rumbles lernt. Beim derzeitigen Stand, ist es jedoch fragwürdig, dass die Rumbles bereits eine überzeugende Qualität besitzen.
Um die Qualität der generierten Sounds weiter zu steigern, braucht es vor allem zwei Dinge: einen größeren, besser beschriebenen Datensatz und die gezielte Anpassung von Modell-Teilen wie dem Vocoder, um mögliche Bottlenecks zu beheben.
Die Möglichkeiten, die solche modularen Text-to-Audio Modelle bieten, sind extrem vielfältig und werden mich sicher in meiner zukünftigen Arbeit stark beschäftigen.
Experimentelles Delay/Feedback Plugin – Resonant Flux
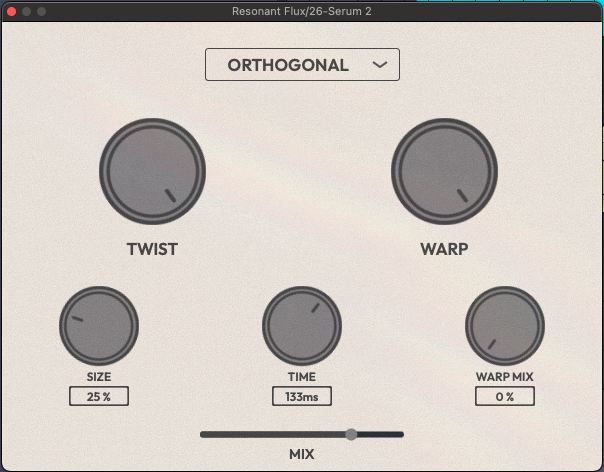
Dieses Plugin entstand als Semesterprojekt im Rahmen der Masterklasse. Das zugrundeliegende Ziel war es, Delay/Feedback als ein intuitives und zugleich ausdrucksstarkes Instrument neu zu interpretieren.
Die ersten Prototypen entstanden in Max for Live, mit dem Fokus darauf, klanglich interessante, aber auch kontrollierbare Feedback-Strukturen zu finden. Ein besonderer Schwerpunkt lag dabei auf der Identifikation größerer Parametergruppen, die sich zu musikalisch sinnvollen Makros zusammenfassen lassen, um trotz der Komplexität ein intuitives, spielbares Interface zu ermöglichen.
Die finale Architektur basiert auf zwei Feedback-Delay-Networks, kombiniert mit resonanten Bandpässen und Sättigung. Die Verschaltung der Delay-Lines erfolgt über definierte Presets, die unterschiedliche klangliche und rhythmische Eigenschaften erzeugen.
Umgesetzt wurde das Plugin schließlich in C++ mit JUCE, inklusive performativer Makrosteuerung über Parameter wie Size, Warp, Twist oder Warp Mix. Diese beeinflussen unter anderem die Delay-Zeiten, Filterung und die Verhältnisse der internen Parameter zueinander, wodurch komplexe Klanglandschaften entstehen.
Im folgenden Video wird der Entwicklungsprozess von „Resonant Flux“ dokumentiert, mit einer anschließenden Sound-Demo des Plugins.
Max for Live – Snare Synth

Als mein Abschlussprojekt in der LV Prototyping & Implementierung bei Patrik Lechner entwickelte ich einen Snare-Synthesizer auf Basis des Karplus-Strong-Algorithmus in Max for Live. Hierbei wird die Delay-Line mit einer Kombination aus Noise- und Square-Transiente angeregt, wobei die Delay-Zeit direkt durch den MIDI-Input gesteuert wird. Die klangliche Färbung des „Snare-Bodys“ erfolgt über einen EQ im Feedback-Pfad.
Ergänzt wird das Ganze durch einen separaten Noise-Layer, der ebenfalls über einen EQ geformt werden kann. Transient, Body und Noise lassen sich individuell mischen, bevor das Signal abschließend durch eine Verzerrung geschickt wird.
Für die Distortion orientierte ich mich an der Übertragungskennlinie von Trash 2 im „Tension Mode“, welche ich in Max nachbildete. Die Form der Verzerrung ist dabei visuell kontrollierbar, zur Veranschaulichung habe ich eine einfache Jitter-Visualisierung integriert.
Das Device erlaubt eine Vielzahl unterschiedlicher Snare- und Percussion-Klänge und findet bereits häufig Einsatz in meinen eigenen Produktionen. Hierbei noch exemplarisch ein Drum-Loop unter Einsatz von diesem aus einer meiner letzten Produktionen.
Signation – School of Champions
Wolfgang Schlögl gab uns bei seinem Workshop zu Film- und Fernseh-Komposition die Einladung, eine Signation (Opening-Theme) zur Serie „School of Champions“ zu gestalten. Mein Ergebnis dazu könnt ihr hier wahrnehmen:
1. Semester
Kurzfilm Vertonung – „Vote!“
Im Rahmen des Unterrichts bei Elisabeth Frauscher vertonte ich mit zwei Kolleg*innen einen Ausschnitt des Kurzfilms „Vote!“. Hierbei bestand der vorhandene Original-Ton nur aus der Musik.
Wir nutzten dabei hauptsächlich selbst angefertigte Foley-Aufnahmen, welche im Studio der FH entstanden. Abschnittsweise wurden Sound-Libraries benutzt und das Sounddesign der „menschlichen Fernseher“ führte ich in Ableton Live durch. Der Rest des Projekts wurde in Avid Pro Tools umgesetzt.